Les karaokés d’anisong avec Karaoke Mugen et le développement de logiciel open-source
EDIT : J’ai rajouté un segment sur la façon dont on organise les branches dans le développement de Karaoke Mugen
EDIT 2 : Je développe un peu les relations qu’on a avec d’autres bases de karaoké
Aujourd’hui je vais vous parler pas mal technique. Ca va être long, et si vous n’êtes pas versé dans l’art de l’informatique, ça ne va pas vous parler des masses. Cependant, si vous vous intéressez à ce domaine ou si vous faites preuve de curiosité, il y a moyen que ce post vous intéresse, voire vous inspire à développer votre propre petit projet (ou à aider Karaoke Mugen !)
Le développement de Karaoke Mugen m’a appris beaucoup de choses que je vais tenter de vous exposer ci-dessous.
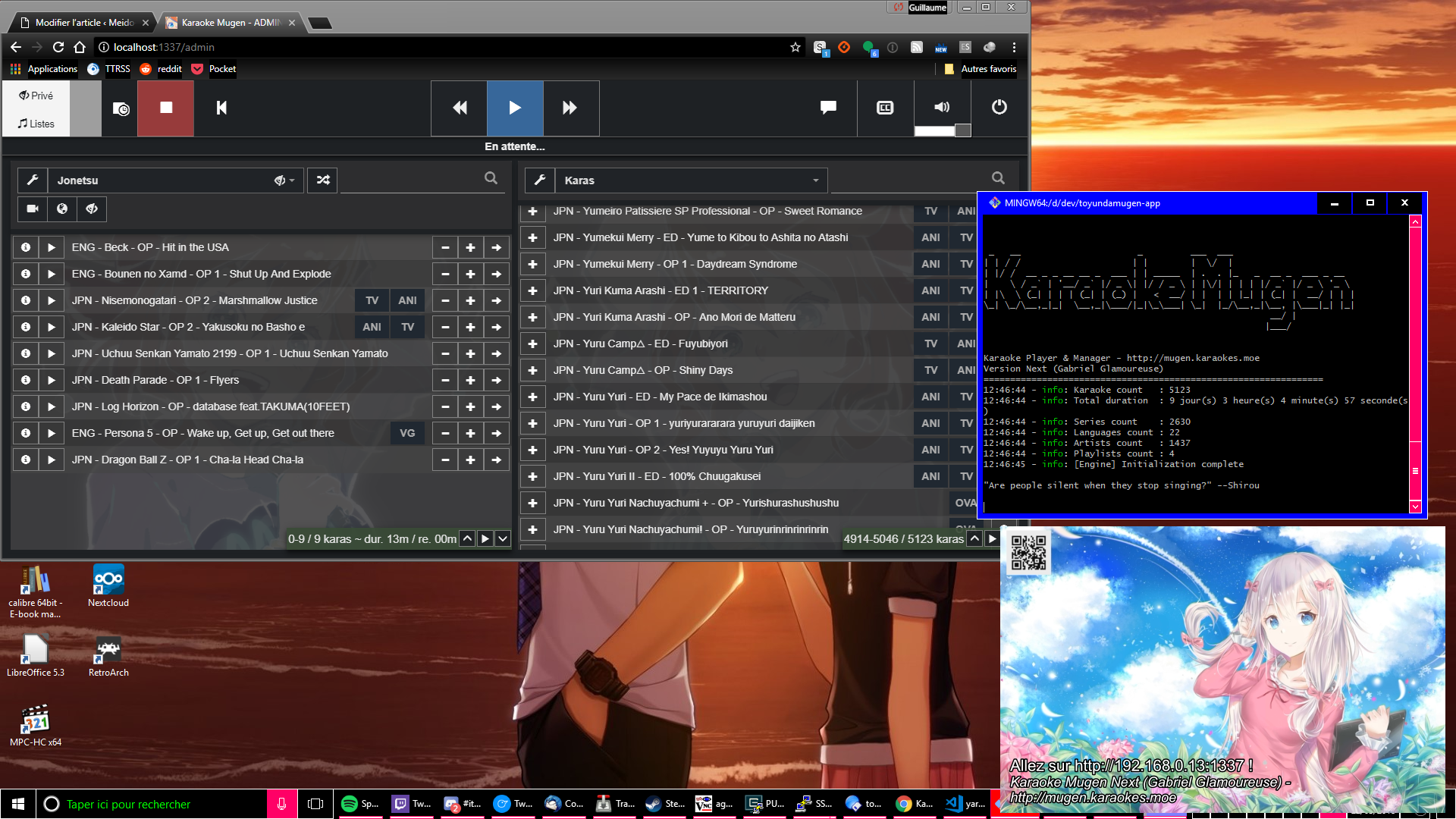
C’est parti !
Le projet
Parce que c’est notre p… euh non, en fait.
Je vais pas revenir vraiment dessus, j’ai déjà parlé en long en large d’où ça venait et pourquoi. Le but de ce post est cependant de vous expliquer un peu plus techniquement comment ça s’est fait.
Les besoins
En gros :
- Permettre aux utilisateurs d’ajouter des karaokés à une liste de lecture, consulter la liste des karas dispos, faire des recherche
- Permettre aux gérants de karaokés, ceux qui choisissent les chansons ou qui font tourner la salle, de gérer la playlist, voire des playlistes différentes.
- Interagir avec un lecteur vidéo
- Le lecteur vidéo doit pouvoir lire des sous-titres ASS par dessus al vidéo et être facilement interfaçable (ça c’est facile, on a retenu mpv, qui en plus est multi-plateformes)
- Créer une base de données de karaokés à partir de fichiers de métadonnées
- L’application doit être portable
- L’application doit fonctionner offline, sans connexion internet. Oui, en 2018.
Quand on fait la somme de tous les besoins, on se rend compte qu’à moins de réinventer la roue et perdre un temps fou, NodeJS paraissait le candidat le plus approprié en terme de langages. Mais comme vous allez voir, ce n’est pas le seul choix qui a été influencé par ces besoins.
Concernant le besoin de portabilité, on se rend comtpe que beaucoup de gens aujourd’hui sont habitués à avoir un site auquel se connecter et tout faire en ligne. Le problème étant qu’avec Karaoke Mugen, on savait qu’Internet ne serait pas toujours disponible, notamment en convention. Bien sûr il y a aussi le problème assez gênant de si un jour le site disparaît, on perd tout. Ah et puis streamer les vidéos en qualité acceptable depuis le net, ce n’était pas toujours une bonne idée.
La conception
Un peu comme avec une histoire, on ne fonce pas tête baissée dans le code. Il y a des tas de choses à préparer avant. Définir par exemple ce qu’on va vouloir que l’utilisateur puisse faire, ce qu’il ne pourra pas faire, et analyser ce dont on a besoin. Typiquement, pour ce qui nous intéresse, il fallait se poser des questions :
- C’est quoi un Karaoké ? Ca se définit comment ? C’est une vidéo, des sous-titres, un titre, une série, un type (opening, ending, etc.), une langue…
- Les séries, y’en a qu’une par karaoké ou plusieurs ?
- L’utilisateur, il a un login, un mot de passe, et quoi d’autre ?
- Une playlist ça contient des karas mais ça a quoi d’autre ? Un nom ?
Ca c’est pour les données de notre application, après il a fallu se poser d’autres questions, notamment sur comment les données intéragissent entre elles.
- L’utilisateur peut ajouter un karaoké à la playlist courante, mais il ne peut pas en retirer.
- L’administrateur doit pouvoir supprimer, créer, et modifier une playlist.
En découpant les différentes actions possibles et en les listant, on arrive à dresser une liste des choses à faire pour que l’application prenne vie.
Là on parle juste des données et de comment elles agissent, mais niveau structure il a fallu penser l’application également en la découpant en morceaux qu’on pourrait interchanger et qui communiqueraient entre eux :
- Un moteur, celui qui reçoit les commandes et les execute, et retourne les résultats. Par exemple quand on demande d’ajouter un karaoké à une playlist, il va vérifier si l’utilisateur a le droit d’ajouter un karaoké, si la playlist existe, si le karaoké existe, si le karaoké n’est pas déjà présent dans la playlist, et retourner un message en conséquence si c’est un succès ou un échec.
- Une interface web, qui permet à l’être humain d’envoyer des commandes au moteur, et de voir le résultat.
- Une API, qui fait le lien entre les deux. Ecrire une API c’est comme écrire un langage : c’est définir des commandes, des mots clés, qui une fois envoyés à l’API donnent des résultats. Par exemple quand on clique sur le bouton pour ajouter un karaoké, ça envoie un message à l’API avec le numéro du karaoké et le numéro de la playlist, et l’API l’envoie au moteur, puis répond s’il y a eu succès ou echec. Ecrire une API a un gros avantage : ça permet à d’autres gens d’avoir un accès aux commandes de Karaoke Mugen, d’automatiser des choses, ou de développeur leur propre interface (par exemple une interface de client mobile). Cela permet aussi d’assainir la chaîne d’execution, c’est à dire ce qu’il se passe entre le moment où on clique sur un bouton et on obteint un résultat.
- Un module pour parler au lecteur mpv, le lecteur de vidéos. Il faut lui faire comprendre qu’on veut charger une vidéo, afficher des sous-titres, aller en arrière, passer à la vidéo suivante… mpv a une API lui aussi, donc on a une liste de commandes qu’on peut lui envoyer pour qu’il comprenne ce qu’on veut faire. Bien sûr que si on veut charger une vidéo on peut dire à l’utilisateur de faire Fichier > Ouvrir, mais le but du jeu c’est quand même que KM parle avec le lecteur vidéo de façon automatique. Tout le sport est là.
- Une interface avec la base de données. Le moteur a besoin de données, que ça soit la liste des karaokés ou le contenu d’une playlist, et pour ça il doit parler un langage commun avec la base.
Il a fallu développer tout ça un peu en parallèle, et ce ne fut pas du tout évident ! Ce genre de réflexions nous a pris toute une journée de réunion.
Les langages
Quand il a fallu choisir un langage, on s’est penchés sur plusieurs choix, notamment Ruby, Python, Go, NodeJS et bien sûr PHP.
Il nous fallait déjà définir sur quoi l’application devait tourner : des ordis sous Windows, Mac et Linux. Le multi-plateforme était primordial. La seconde contrainte était que ça soit facile à utiliser. Un double-clic et hop ! Avec la v1 de Karaoke Mugen, on avait un truc crade où on embarquait un interpréteur PHP sous Windows. Sous Mac il était fourni d’office et sous Linux il fallait le faire installer. Pas top donc. J’ai rien contre les utilisateurs de Linux mais je pars quand même du principe que ceux qui utilisent Linux pour leur desktop doivent savoir se débrouiller en informatique : ils l’ont cherché.
Pour Karaoke Mugen v1 on avait un lanceur codé en NodeJS. Mais NodeJS c’est comme PHP, il faut que ça soit interprêté. Et là, on est tombé sur pkg de zeit, un outil permettant d’embarquer Node dans un executable pour Windows, Linux et Mac. On a pas trouvé d’outil similaire pour Ruby ou Python ou Go. Enfin si, pour Python y’avait pyfreeze et py2exe mais tous deux plus ou moins à l’abandon. NodeJS en plus de ça fournissait toute l’architecture pour être à la fois une application web (pour que les gens interagissent avec) et une application standard, attendant des évènements pour faire des actions.
Les désavantages de Node
Node c’est cool, mais on va pas se voiler la face.
- C’est quand même une petite usine à gaz. Pas au niveau d’une zone industrielle mais hein, une petite usine quand même.
- L’asynchrone c’est cool, mais c’est pas tout le temps évident. Faire une pause dans son logiciel est absolument contre-intuitif. Il faut bien comprendre que Node est asynchrone, ça veut dire que votre code n’attend pas que la commande précédente soit terminée avant de s’executer. J’y reviendrai plus tard, mais au début surtout, une certaine gymnastique mentale est requise.
- L’écosystème de packages est hyper riche mais inégal. On peut tomber sur des packages super bien, très documentés, faciles à utiliser, et d’autres absolument inbitables, à la documentation inexistante, et parfois même avec des bugs et laissés à l’abandon. Le véritable problème vient surtout de NPM, le gestionnaire de packages attitré (mais c’est pas le seul heureusement) de Node. NPM sur le papier est bien, mais en pratique il est très lent et surtout son moteur de recherche est très mal foutu et fera remonter parfois des packages dont vous n’avez que foutre quand vous cherchez quelque chose, comme par exemple comment faire une barre de progression dans le terminal.
- Le Javascript de base, c’est très moche, et il faut passer par des outils comme Babel (j’y reviendrai aussi) pour assainir le code et fournir pas mal de facilités d’écriture. Je vais pas faire un cours sur Babel maintenant mais en attendant que Node prenne en compte toutes les subtilités du langage Javascript évolué, Babel est très pratique. Plus d’infos plus tard.
La base de données
On nous a souvent demandé, pourquoi ne pas avoir une base de données tout simplement comme base, plutôt que de travailler avec des fichiers ?
Comme il s’agit avant tout d’un travail collaboratif, l’utilisation de git ou de svn impliquait que la granularité des modifications soit faite au niveau des fichiers. C’est à dire que, si on avait qu’un seul gros fichier (binaire en plus) dans lequel tout était stocké, on aurait aucun moyen d’annuler ou d’inspecter des modifications, alors qu’on peut très facilement faire ça avec une myriade de petits fichiers de données. Cela allait grandement faciliter les choses aussi pour résoudre des conflits potentiels de modification.
Mais on ne pouvait pas faire avaler à l’application tous les fichiers de métadonnées (il y en a plus de 5000) à chaque lancement, il fallait donc réfléchir à un moteur de base de données (un SGBD) et à une étape de génération (transvaser les informations des fichiers de métadonnées, qu’on va appeler à partir de maintenant des .kara, vers la base). La base de données était nécessaire car on avait besoin d’une base relationnelle où des éléments sont reliés entre eux. Par exemple, on voulait pouvoir faire en sorte d’avoir des tags, des séries, et des karaokés. Un karaoké peut appartenir à une ou plusieurs séries, et chaque série peut avoir plusieurs karaokés.
On a donc regardé ce qui était disponible, et comme notre application devait être portable, les gros mastodontes comme MariaDB/MySQL, PostgreSQL, MondoDB ou que sais-je encore, n’étaient absolument pas adaptés car ils reposaient sur le principe d’une architecture client-serveur : en gros votre base de données est sur un gros serveur, le client s’y connecte, l’interroge, prend ses données et s’en va. Ici, le client et le serveur sont la même entité (l’application Karaoké Mugen). SQLite a donc été tout indiqué.
SQLite a donc été choisi. Ce n’est pas un choix si anodin puisque ce moteur de base de données est pensé pour être transportable. En gros il s’agit juste d’une librairie (un paquet de petites fonctions qu’on rajoute à son programme pour les réutiliser) qui permet de créer et d’accéder à des données avec le langage SQL. Le SQL est très pratique pour « demander » des choses à une base de données car c’est un langage facile à comprendre et bien articulé. Cerise sur le gâteau il est standardisé et donc utilisable partout…
…enfin à peu près. Chaque moteur de base a ses particularités et dans SQLite il y a « Lite » comme « Je sais pas faire un ALTER TABLE pour supprimer une colonne *rire débile* ». En gros, il y a des petites spécificités et des choses qui manquent dans SQLite qui nous ont parfois tapé sur les nerfs, mais globalement on a réussi à s’en tirer sans trucs trop hardcores…
DELETE FROM blacklist;
INSERT INTO blacklist (fk_id_kara, kid, created_at, reason)
SELECT kt.fk_id_kara, k.kid, strftime('%s','now') ,'Blacklisted Tag : ' || t.name || ' (type ' || t.tagtype || ')'
FROM blacklist_criteria AS blc
INNER JOIN karasdb.tag t ON blc.type = t.tagtype AND CAST(blc.value AS INTEGER) = t.pk_id_tag
INNER JOIN karasdb.kara_tag kt ON t.pk_id_tag = kt.fk_id_tag
INNER JOIN karasdb.kara k on k.pk_id_kara = kt.fk_id_kara
WHERE blc.type BETWEEN 1 and 999
AND kt.fk_id_kara NOT IN (select fk_id_kara from whitelist)
UNION
SELECT kt.fk_id_kara, k.kid, strftime('%s','now') ,'Blacklisted Tag by name : ' || blc.value
FROM blacklist_criteria blc
INNER JOIN karasdb.tag t ON t.NORM_name LIKE ('%' || blc.value || '%')
INNER JOIN karasdb.kara_tag kt ON t.pk_id_tag = kt.fk_id_tag
INNER JOIN karasdb.kara k on k.pk_id_kara = kt.fk_id_kara
WHERE blc.type = 0
AND kt.fk_id_kara NOT IN (select fk_id_kara from whitelist)
UNION
SELECT k.pk_id_kara, k.kid, strftime('%s','now') ,'Blacklisted Series by name : ' || blc.value
FROM blacklist_criteria blc
INNER JOIN karasdb.kara k ON s.NORM_name LIKE ('%' || blc.value || '%')
INNER JOIN karasdb.serie s ON s.pk_id_serie = ks.fk_id_serie
INNER JOIN karasdb.kara_serie ks ON ks.fk_id_kara = k.pk_id_kara
WHERE blc.type = 1000
AND k.pk_id_kara NOT IN (select fk_id_kara from whitelist)
UNION
SELECT CAST(blc.value AS INTEGER), k.kid, strftime('%s','now') ,'Blacklisted Song manually'
FROM blacklist_criteria blc
INNER JOIN karasdb.kara k ON k.pk_id_kara = blc.value
WHERE blc.type = 1001
AND CAST(blc.value AS INTEGER) NOT IN (select fk_id_kara from whitelist)
UNION
SELECT k.pk_id_kara, k.kid, strftime('%s','now') ,'Blacklisted Song longer than ' || blc.value || ' seconds'
FROM blacklist_criteria blc
INNER JOIN karasdb.kara k on k.videolength >= blc.value
WHERE blc.type = 1002
AND k.pk_id_kara NOT IN (select fk_id_kara from whitelist)
UNION
SELECT k.pk_id_kara, k.kid, strftime('%s','now') ,'Blacklisted Song shorter than ' || blc.value || ' seconds'
FROM blacklist_criteria blc
INNER JOIN karasdb.kara k on k.videolength <= blc.value
WHERE blc.type = 1003
AND k.pk_id_kara NOT IN (select fk_id_kara from whitelist)
UNION
SELECT k.pk_id_kara, k.kid, strftime('%s','now') ,'Blacklisted Title by name : ' || blc.value
FROM blacklist_criteria blc
INNER JOIN karasdb.kara k ON k.title LIKE ('%' || blc.value || '%')
WHERE blc.type = 1004
AND k.pk_id_kara NOT IN (select fk_id_kara from whitelist)
Oui bon OK ça c’était la requête SQL de création de la liste noire des karaokés selon les critères que vous aurez mis dans la table des critères, et comme un critère peut être un karaoké, un nom de karaoké, un tag spécial, etc. Et encore, l’autre grosse requête c’est pour récupérer le contenu d’une playlist, avec toutes les infos que ça comporte… J’imagine sans peine que certains d’entre vous bouffent ce genre de requêtes à longueur de journée, mais pour nous ce n’était pas immédiatement évident.
Bref, c’était parti pour utiliser SQLite !
La license
Très tôt dans le développement s’est posé la question de quelle license utiliser. J’avoue avoir une vision assez bizarre du monde du libre et de l’open source (oui, c’est différent, faites attention à ce que vous dites malheureux !). J’aime bien les principes du libre mais je ne me sentais pas utiliser une license de type GPL tout simplement parce qu’elle était trop contraignante. Dans mon esprit, je me suis dit « Hé mais la liberté, c’est quand même d’être libre de faire ce qu’on veut ». Le site Choose a License m’a du coup bien aidé à choisir, et mon choix s’est porté sur la license MIT. J’ai bien sûr demandé à ceux qui avaient déjà participé au code et tout le monde était d’accord. Pour ceux qui auraient la flemme de lire cette license, en gros c’est « Faites ce que vous voulez, je ne suis pas responsable, mais vous devez me créditer si vous utilisez mon code. » Il est vrai que j’ai longtemps hésité avec la GPL, mais la GPL c’est aussi beaucoup d’emmerdes pour la faire respecter. Au moins là je sais à quoi m’en tenir. Si la licene doit changer un jour, je pourrai sans problème contacter les contributeurs (je sais où ils habitent, haha.) Mais pour ça il faudrait vraiment un vrai coup de pute de quelqu’un qui prendrait Karaoke Mugen pour ses propres besoins et ne jouerait pas le jeu de rendre un peu à la communauté ce qu’il a pris.
La license de la base de karaokés est la même, je n’ai pas cherché plus loin. Sauf que pour la base de karaokés, il y a l’épineuse question des vidéos qui n’appartiennent pas au projet Karaoke Mugen mais à leurs ayants droits respectifs. C’est une question sacrément complexe et très « zone grise » du projet.
Les outils
Un artisan travaille avec de bons outils, et ça tombe bien car pour peu qu’on cherche, on trouve de tout sur le net.
L’éditeur
Pour écrire du code, il faut un éditeur de texte. Pas mal de monde m’avait recommandé Sublime Text qui en soit est très bien, mais je n’ai jamais réussi à vraiment m’y faire. Par contre, j’avais pas mal entendu parler de Visual Studio Code. Attention, pas Visual Studio le mastodonte de Microsoft, mais son petit frangin. VSC est non seulement gratuit, mais en plus de ça open source et tourne partout. Ouais, dingue pour un produit Microsoft. Mais s’il y a bien un truc que MS sait faire dans la vie c’est les outils pour développeurs et le matériel. C’est con que Windows soit leur principal produit quand même, alors que c’est celui qui est le moins bien foutu…
VSC a beaucoup d’atouts pour lui et j’ai trouvé son interface hyper claire. Il est également bardé d’extensions développées par la communauté, des trucs aussi cons que de la coloration syntaxique adaptée à un upload FTP automatique quand on sauvegarde, et j’en passe. Je l’ai très rapidement adopté et aujourd’hui je ne sais pas comment je m’en passerais .
Néanmoins, il faut garder à l’esprit que chacun trouve chaussure à son pied d’une manière ou d’une autre. Moi j’aime bien VSC, mais je connais des gens très fréquentables qui se contenteront de Notepad++ oui qui sortiront l’artillerie lourde avec Webstorm. Loin de moin l’idée de faire une guerre de clochers, tant que vous êtes à l’aise avec votre éditeur de prédilection c’est tout ce qui compte, mais il faut garder l’esprit ouvert et voir ce que fait la concurrence, c’est toujours intéressant.
Un éditeur c’est bien, mais outre la coloration syntaxique, il fallait aussi un linter, c’est à dire un outil qui scanne votre code et repére les choses mal écrites. Pèle-mêle :
- Les variables déclarées mais pas utilisées
- Les variables utilisées mais pas déclarées (sans déconner)
- Pareil avec les fonctions
- L’identation
- Les ouvertures de parenthèses et autres crochets.
- L’utilisation d’un await dans une fonction pas synchrone…
Et j’en passe… l’idée d’un linter c’est de vous montrer où vous écrivez de la merde, et de prévenir le plus possible les problèmes pendant que vous écrivez. Pour NodeJS, on a ESLint, qui s’interface très bien avec Visual Studio Code :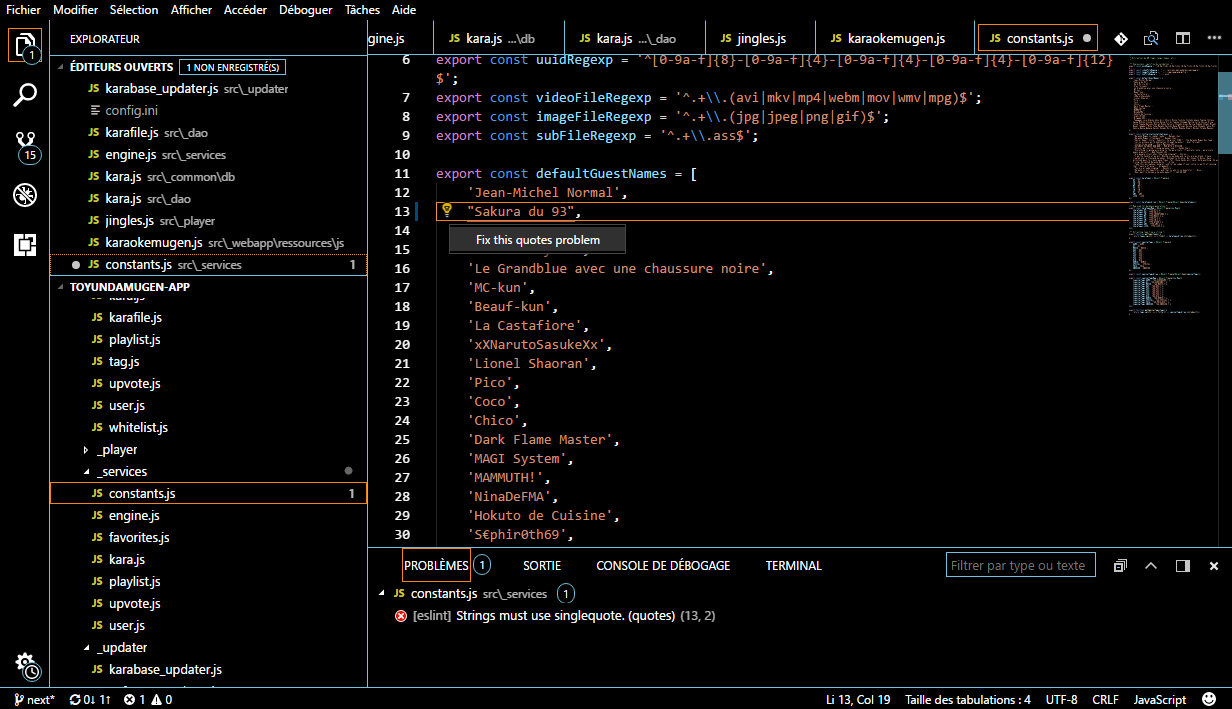
Je pourrais parler de débuggueur, mais je ne me suis jamais vraiment penché dessus. La plupart du temps j’arrive à trouver le problème et la solution 
Les tests
Je vais pas trop m’étendre sur le sujet car c’est surtout Aeden qui se charge des tests unitaires. C’est quoi un test me demanderez-vous : c’est simple. Votre application est sensée marcher. Karaoke Mugen ne devrait pas planter quand on ajoute un karaoké, quand on s’y connecte ou quand on consulte la playlist publique. Du coup il faut écrire une série de tests, où on utilise l’API pour faire croire qu’on utilise l’application, en lui donnant des ordres et en voyant comment elle répond. Comme on sait ce qu’elle doit répondre (OK, pas OK, etc.) on est capable de dire si le test est réussi ou pas. Les tests unitaires ne peuvent jamais tout prévoir nibeau bugs, mais ils permettent de voir si on a cassé quelque chose, surtout si on les fait souvent après de grosses modifications. Pour les tests, on utilise Mocha et Supertest
Le stockage des sources
Pour travailler en commun les gens ont souvent l’habitude d’utiliser Google Drive ou Dropbox. Rien de mal à ça, ces deux exemples ont l’avantage d’être rapides et faciles à utiliser. Mais quand on fait du code, on a besoin d’un truc que ces deux-là ne peuvent pas vous offrir : la gestion des conflits de mise à jour, l’assurance qu’une écriture s’est bien passée et la possibilité d’avoir plusieurs versions d’un même fichier voire carrément de tout votre projet tout en optimisant la place que ça prend.
C’est sûr que dans GDrive ou Dropbox on peut copier tout un dossier et l’appeler « Version 2 » mais l’espace est utilisé deux fois, et rien ne dit que quelqu’un n’ira pas faire mumuse avec cette version sans que vous ne le sachiez.
Le rôle d’un gestionnaire de versionning, comme git ou SVN, c’est vraiment d’offrir un moyen sécurisé et fiable de travailler sur la même chose. Ainsi, quand vous faites une modification, un « commit », vous dites à git par exemple « J’ai modifié tel fichier, j’ai remplacé telle ligne par telle ligne. » et lui l’enregistre dans son journal. Quand quelqu’un d’autre fait la même chose, il l’enregistre dans son journal, et est ainsi capable de dire qui a modifié quoi, quand, et surtout, à partir de quelle version. Ainsi, si vous travaillez en même temps sur le même fichier, git permet de dire « Attention, vous avez deux modifications sur le même fichier, laquelle dois-je garder? » et à vous de voir ensuite comment fusionner ça.
git permet plein d’autres choses mais je ne vais pas entrer dans les détails dans ce billet : sachez juste que c’es tun outil indispensable quand on travaille sur un projet qui requiert du texte. Il n’est pas très adapté pour les fichiers binaires, documents Office et autres images, c’est pour ça qu’on en stockera le moins possible dans un dépôt git.
Le defacto standard pour créer un dépôt git est github, mais certains n’aiment pas trop que tout le code de la planète soit centraliser quelque part. Si github tombe, et il est déjà tombé, c’est des tas de programmes qui ont des dépendances stockées sur github qui ne pourront plus compiler. Comme je voulais tester des trucs et aussi apprendre, j’ai décidé d’installer une instance gitlab : il s’agit du Lab de Shelter. C’est comme github, mais hébergé chez soi. C’était pas évident à mettre en place vu tout ce qu’on peut faire avec, mais ça permet de bien s’organiser.
On a du coup crée un groupe Karaoke Mugen, avec autant de dépôts que nécessaire aux différents projets.
Outre un dépôt git, gitlab offre également un gestionnaire de tickets sommaire mais efficace, et d’autres petites joyeusetés. Les tickets, ce sont les « problèmes » d’un logiciel. Quand vous avez un problème, vous ouvrez un ticket et vous attendez qu’un développeur s’occupe de votre souci. On a commencé par créer des étiquettes afin de classifier les différents tickets (bug, webapp, player, etc.) comme ça on peut ranger plus efficacement, trier par priorité, etc.
Enfin, il y a les milestones, qui sont des points d’étape. On définit un point d’étape comme par exemple « Version 2.0 » et on y assigne des tickets. Comme ça, on peut dire « ça ça sera résolu dans telle version » ou encore avoir un aperçu de ce qu’il reste àf aire avant que telle version soit finalisée.
L’organisation
J’ai déjà parlé un peu de l’organisation à l’instant avec gitlab qui est une forge logicielle, c’est à dire une suite complète d’outils pour travailler en groupe. Mais avant de mettre les mains dans le camboui, il est important de mettre certaines choses au clair
La base
Je vais parler rapidement de la base de Karaoké Mugen car c’est pas le sujet principal de ce billet, mais avant de travailler sur l’application il était important d’uniformiser les données. Parce que modifier le format des données pendant le développement c’est pas toujours une bonne idée. Malheureusement on ne peut pas toujours tout prévoir ni lire l’avenir, et c’est arrivé.
Globalement, il a fallus ‘assurer qu’on avait des métadonnées qui étaient toutes écrites de la même façon pour que le logiciel puisse les relire et les interpréter. Décider de comment on stocke les dates par exemple (date d’ajout, date de dernière modification) ou comment on définit les langues… Par exemple, un truc qui a été défini très vite, c’est les langues. Un karaoké peut être en français, japonais, anglais, ou allemand par exemple, mais jusqu’ici on stockait ces noms de langue en mode yolo, « FR » pour français, « JAP » pour japonais… Cette nomenclature est issue de la base originelle échapée d’Epitanime. Mais en vrai ça ne correspond à aucune norme. Car il existe des normes pour les langues, notamment la norme ISO 639-2B. Cette norme définit des codes à trois lettres et à quelle langue ils correspondent. La question de ce choix de norme s’est posé quand on a voulu internationaliser Karaoke Mugen : permette qu’il existe une traduction française, anglaise, allemande, etc. Et pour ça il fallait rendre plein de choses variables dont… les noms des langues de karaokés ! Plutôt que de faire un fastidieux dictionnaire des langues, l’écosystème Node est si bien fait que quelqu’un a déjà pensé à ça et a crée un module qui fournit ça à notre application : iso-countries-languages on a ensuite interfacé ça avec le module langs car iso-countries-languages ne prenait que des codes à 2 caractères. Or on en avait besoin de trois car certains karas sont dans des langues indéfinies (le code « und » n’existait pas sur la norme à 2 caractères). Langs permettait de faire le lien en traduisant un code à trois caractères en code à deux, et ainsi on pouvait obtenir le nom d’une langue dans n’importe quelle langue. Le Français ne s’écrit pas « Français » en anglais après tout mais « French ».
Voici un des nombreux exemples qui nous ont forcé à revoir comment la base de karaokés était architecturée.
Après pour parler organisation pure, il a fallu mettre en place un FTP commun pour gérer les mises à jour de vidéos et surtout expliquer à tous les participants comment on utilisait git et surtout comment ajouter ou modifier un kara existant…
L’application
Comment on s’est organisés pour l’application, c’est plutôt simple : il a fallu définir comment on organisait les dossiers, faire un squelette de l’application en quelque sorte. Un des développeurs, Mathieu Delestre, nous a en quelque sorte « kickstarté » en faisant une ébauche qui permettait un peu succintement de piloter le player avec une playlist faite à la main. C’était vraiment les tous débuts et c’était pas utilisable, mais on pouvait commencer à bâtir sur ça.
Au final on a rebâtit tout de zéro ou presque avec la version 2.1 mais vous allez voir pourquoi ensuite.
L’organisation des branches
J’ai pas mal parlé en novembre des différentes branches de KM. Il faut savoir que via git on peut avoir des « branches », c’est à dire des versions du logiciel qui évoluent chacune de leur côté. Quand on travaille sur une nouvelle fonctionnalité on fait une branche dédiée à ça, c’est une copie de KM, et on travaille sur cette copie. Git permet de passer d’une copie à l’autre en un clin d’oeil. Quand on a terminé de travailler sur la copie, on fait une demande pour que les modifs de notre copie soient intégrées sur la version de base. C’est une sécurité et ça permet d’isoler les soucis quand on développe une nouvelle fonction dans le logiciel : on ne fout pas le bordel avec la version que tout le monde utilise.
Souvent, les développeurs font plusieurs branches, une de développement, une pour les tests, une pour le logiciel en production, etc. Nous on a juste fait deux branches : master (qui est la production, la version que tout le monde utilise au moment où j’écris ces lignes) et une seconde qui s’appelle next, sur laquelle on met toutes les nouvelles fonctions. Lorsque viendra le moment de sortir la 2.1, on appliquera toutes les modifications de next sur master, et le tour sera joué.
En ce qui concerne le « flow » de développement, pour chaque problème ou fonctionnalité on crée une issue dans gitlab, un ticket quoi, puis quand on se met à travailler dessus on crée une demande de fusion, ce qui crée une nouvelle branche avec le nom de notre ticket. On travaille sur cette branche et quand on a fini on fusionne sur next pour l’intégrer. C’est plutôt sain comme fonctionnement, même si je laisse beaucoup de libertés à ceux qui travaillent sur KM : ils peuvent fusionner sans me demander sur master ou sur next. Parce que je leur fais confiance, mais avec des développeurs externes, qui viendraient contribuer, il faut bien qu’ils ne bossent uniquement que sur leur branche.
Quand on est pas développeur atitré pour un projet, on peut même faire une « fourche » ou un « fork » en anglais. Il s’agit de carrément copier tout le dépôt dans un espace où on est le maître dessus, faire ses modifs, puis proposer ces modifications au projet principal. On a déjà eu quelques unes de ces « pull requests » pour Karaoke Mugen
Développement de KM
Dans cette partie on va vraiment aborder de la technique pure.
Première version
Je vais pas revenir sur la version 1.0 de Karaoke Mugen faite en PHP car elle n’a pas beaucoup d’intêret, mais plutôt parler des versions avant la 2.0. Là où tout à commencé, avec la version 2.0-alpha. Vous voyez, ce qu’il y a de bien avec git c’est qu’on peut retrouver facilement les premières versions comme si c’était hier !
Si le tout fonctionnait, il y avait encore de nombreux bugs et des features pas encore implémentées ou mal implémentées. Le but d’une alpha, c’est avant tout de vendre des accès anticipés sur Steam et… ah on me souffle dans l’oreillette que c’est pas ça du tout. Plus sérieusement, une alpha c’est fait pour vérifier que on a un concept qui marche, même si c’est loin d’être gagné. Tout n’est pas encore fonctionnel à 100% et il y a des bugs : c’est normal et faut pas en avoir honte. Ca a été l’occasion pour de nombreuses personnes de tester l’application et d’ouvrir plein de tickets.
Puis vint une 2.0-beta, puis une beta2 : vous remarquerez en cliquant sur le lien que j’avais écrit un beau changelog, c’est à dire un journal des changements. C’est une étape importante quand on développe un logiciel car ça permet aux gens de savoir ce qui a été modifié sans se taper l’itnégralité des commits du dépôt git entre deux versions. Beaucoup de gens ne font pas attention à la documentation alors que c’est PRIMORDIAL, mais on verra ça plus tard.
La route vers la 2.0
Mine de rien, débugguer et ajouter les dernières features n’est pas tout quand on veut sortir une application pour le grand public. Il faut la tester, la re-tester, et ce parfois dans des environnements hostiles (comme un Raspberry Pi). On a sorti une version Release Candidate (RC) avant la 2.0.0 finale. Qu’est-ce qu’une RC? C’est une version presque finale, c’est à dire dont il ne reste plus que quelques bugs à corriger.
Cependant, avant ça, il fallait s’occuper du site web et de la doc, qu’on verra plus bas : mais tout ça a pris beaucoup de temps à régler. Il fallait également choisir les outils à utiliser, les mettre en place, les apprendre… tout en jonglant avec les retour sutilisateurs, les corrections de bugs de dernière minute… Et je ne parle même pas des optimisations ! Que cela soit moi ou Ziassan qui étions les deux principaux développeurs à l’époque de la sortie, nous apprenions sur le tas, et nous avons découvert certaines choses très tardivement durant le développement. Par exemple comment mieux écrire le code (vous allez voir ça juste en dessous) ou encore comment au lieu d’écrire l’adresse web à laquelle se connecter sur le papier-peint du player avec une librairie comme jimp qui était lourde et prenait un temps fou à s’executer, on a préféré utiliser des fonctionnalités internes à mpv pour superposer du texte à une image ou vidéo. Ce code-ci par exemple est devenu totalement inutile
De la même façon, un truc qu’on faisait avec la toute première version de Karaoke Mugen, c’était d’afficher au lancement d’une vidéo des infos comme le nom de la chanson, la série, et le type de karaoké (opening, ending, etc.) Pour faire cela, on éditait le fichier de sous-titres pour ajouter ces mentions dedans avant de passer les sous-titres à mpv. C’était lourd et hasardeux : on devait deviner la bonne taille de police à mettre et d’autres joyeusetés. Et puis on a découvert cette histoire de texte affichable sur la vidéo via mpv, et ça a éliminé beaucoup de code devenu inutile et c’était beaucoup plus fiable de faire afficher ces infos à mpv quelques secondes plutôt que de toucher au fichier de sous-titres, surtout que mpv affichait une taille relative à la taille de la fenêtre, ce qui était parfait. Pour vous donner une idée du code originel de cette fonction, vous pouvez le consulter ici
La route vers la 2.1
On s’est rapidement heurté à un mur en pensant à de nouvelles fonctionnalités : pour la plupart d’entre elles il allait nous falloir un système de gestion des utilisateurs, et c’était pas aussi simple que ça en avait l’air. Il fallait non seulement gêrer la vérification de l’authentification de l’utilisateur (vérifier que c’est bien lui, qu’il existe toujours), mais aussi la création et la modification de profil… N’importe qui vous dira que c’est genre une des choses les plus pénibles à gérer, car qui dit utilisateur dit questions de sécurité. Comment on différencie un administrateur d’un utilisateur normal, comment fait-on pour être sûr qu’il ne peut pas accéder à des choses auxquelles il n’a pas droit ?
On ne pouvait pas masquer les choses dans l’interface vu qu’un petit malin aurait pu passer par l’API, il fallait donc prévoir beaucoup de choses et de cas possibles. Pour voir la liste de ce qui a été fait et de ce qu’il reste à faire, direction la milestone 2.1 sur le lab
Mais un plus gros chantier, dans l’ombre, nous attendait…
ES2015+
Une fois la 2.0 sortie il a été décidé qu’on devait revoir certaines choses, car le code de Karaoke Mugen était vraiment très fouilli. Notamment parce qu’on avait travaillé avec une écriture beaucoup trop lourde en JS classique, alors que le JS est comme tout langage, il évolue, et il a des normes de JS plus modernes. C’est ce qu’on appelle la norme « ES ». Node obéit bien à la norme ES5, mais il n’a pas encore implémenté tout des autres normes. C’est pour ça qu’on utilise un transpileur. Un transpileur est souvent utilisé en navigateur, et vous allez comprendre son intêret rapidement : le transpileur réécrit votre code moderne en code dégueulasse pour que les navigateurs plus anciens tels que Internet Explorer puissent les lire. C’est une technique utilisée partout afin de faire des choses complexes sur les pages que votre navigateur lit. Dans le cas de Node, le transpileur agit pour faire comprendre à Node le code qu’il doit lire pour éxecuter votre application. C’est ce que fait par exemple Babel. Parmi les choses que Babel fait, il y a par exemple l’importation de fonctions.
Quand vous voulez utiliser, par exemple, la fonction de choix aléatoire d’élément de la librairie Lodash, en javascript normal vous devez écrire :
const lodash = require('lodash');
Cela va placer dans la variable « lodash » le contenu de la librairie lodash. OK mais vous avez besoin juste d’une seule fonction de la librarie! Avec Babel, ça se passe comme ça :
import {sample} from 'lodash';
Ainsi, on a juste accès à une seule commande (sample) et ça va plus vite que de charger toute la librairie.
Et s’il n’y avait que ça…
Les promesses en async/await
On va la faire simple, vous voyez ce genre de code imbitable ? Cela utilise des promesses, car en Node, comme je l’expliquais, tout est asynchrone, et pour s’assurer qu’on execute bien quelque chose dés qu’une autre fonction est terminée, on écrit ce qu’on appelle une « Promesse ». Cela indique à Node que pour executer la suite, ce qu’il y a à après le .then(), il doit attendre que la fonction ait fini son travail. Ici c’est pour l’initialisation de la base de données, mais un exemple plus simple serait un fichier qui est téléchargé via le net, et la lecture de ce fichier qui n’est executée qu’une fois le fichier fini de télécharger. Ici on est obligé d’avoir une structure ainsi :
OuvertureBDD()
.then(() => {
InsèreDesDonnées()
.then(() => {
AfficheDesDonnées()
.then(() => {
FaisCuireDesCrèpes(miam)
...
)}
)}
)}
Comme vous pouvez le voir ça devient vite relou.
Mais avec du JS moderne, on peut utiliser la façon d’écrire en async/await :
await openUserDatabase();
await migrateUserDb();
if (doGenerate) await generateDatabase();
await closeKaraDatabase();
await getUserDb().run('ATTACH DATABASE "' + karaDbFile + '" as karasdb;');
await compareDatabasesUUIDs();
logger.debug('[DBI] Database Interface is READY');
C’est tout con mais avec la commande await, l’execution s’arrête tant que la fonction appellée n’a pas terminé. Ca rend la vie bien plus simple et pour ça il suffit de déclarer la fonction qu’on appelle en « async function » au lieu de « function ».
Des fois on peut se faire avoir en appelant une fonction asynchrone sans le « await », dans ce cas Node n’attend pas avant de passer à la suivante.
Ecrire en async/await ça sauve des chatons, vous n’avez pas idée, et c’est bon pour la santé ! Plu ssérieusement, ça vous évite d’indenter comme des porcs votre code, et vous pouvez même faire un « catch » global pour chopper la moindre erreur de votre chaîne de fonctions. Il n’y a ni callbacks ni resolves à faire dans chaque fonction, car le retour a été uniformisé avec les fonctions synchrones. On utilisera dans chaque fonction asynchrone le mot clé « return » pour retourner ce qu’on veut retourner à l’issue de la fonction.
Pour vous rendre compte en profondeur, je vous propose de comparer l’arbre des fichiers de code de Karaoke Mugen 2.0.7 (la version stable à l’heure où j’écris ces lignes) et la version Next (qui sera la 2.1)
Les dépendances de Karaoke Mugen
Un truc que j’aime bien faire quand je regarde une app, c’est voir de quoi elle dépend. Vous vous en doutez, on ne réinvente pas la roue tout le temps quand on développe un logiciel : on se sert parmi des librairies, des bouts de code que des gens ont fait avant nous et mis à disposition de tous. Avec node, ça se fait via NPM, et des packages, y’en a des tonnes, vraiment des tonnes. Voir ce que les autres utilisent permet parfois de découvrir des perles méconnues, mais si je devais donner un seul lien, ça serait celui de Awesome NodeJS, un dépôt git où est listé plein de bons sites et bons packages pour votre projet Node. Vous y verrez des trucs hallucinants dans la catégorie « Mad science. »
Petite parenthèse avant de détailler ce qui est utilisé dans KM : en général on essaye d’utiliser des packages qui sont utiles, dans un projet, ou ceux qui ont le moins de dépendances possibles, ceci afin de ne pas surcharger l’arbre des dépendances. Du coup, il m’est arrivé parfois d’écrire certaines fonctions, comme récemment où j’ai viré momentjs pour écrire juste les fonctions dont j’avais besoin (afficher une durée de façon humaine et calculer une date) car momentjs est très volumineux comme librairie, et très complète, mais on avait pas besoin de tout.
Il y a toujours deux écoles : ceux qui préfèrent développer par eux-mêmes toutes les fonctions ou presque pour leurs beosin et ceux qui veulent réutiliser le plus possible de fonctions. Les deux approches se valent, en vrai. D’un côté il y a ceux qui ont le temps et l’envie, et d’autres qui préfèrent se concentrer sur le coeur de leur application et utiliser des briques préexistantes pour gagner du temps. On voit souvent des articles alarmistes parlant de dette du code en ayant un arbre de dépendances complexe pour certaines applis, mais comment faire, en 2018, pour développer des applications en temps et en heure sachant qu’on demande toujours plus de choses à des apps ? On s’en est aperçus en développant KM : on a rajouté des fonctionnalités qu’on avait pas prévues au départ au fil de l’eau ou suivant certains retours, parce que plus ça va, plus on en demande aux apps. Ce n’est pas un reproche hein : c’est juste une constatation que c’est l’évolution naturelle des choses.
Un autre point intéressant sur le fonctionnement de npm et du dossier node_modules dans lequel vont toutes vos dépendances, c’est que vos dépendances ont besoin d’autres dépendances, parfois les mêmes que d’autres modules. Cependant, pas forcément de la même version. Le module A peut avoir besoin du module C en version 1.2, tandis que le module B peut le vouloir en version 1.0. Autant de versions sont stockées dans le dossier node_modules et c’est parfois délicat de vouloir tout optimiser. Présentement, le dossier node_modules de Karaoke Mugen fait une centaine de méga-octets, et environ 150 si vous installez les outils de développement. Ca fait beaucoup comme ça mais heh, c’est du code non compilé aussi.
Mais voyons un peu ce dont Karaoke Mugen a besoin, et pourquoi. Vous pouvez voir le fichier package.json de la version Next, vu que c’est celui le plus à jour. En node, le package.json est un peu la carte d’identité et le livret de famille d’une application.
- ass-parser : Les sous-titres de karaoké étant au format ASS, on avait besoin d’une librairie nous permettant de déchiffrer les fichiers et d’en ressortir ce qui nous intéresse. Dans notre cas ça permet à l’interface web de Karaoke Mugen d’afficher les paroles d’une chanson !
- basic-ftp : Utilisé pour la mise à jour de la base de Karaoke Mugen notamment. Hé oui, il faut bien aller télécharger ces vidéos d’une façon ou d’une autre !
- body-parser : Librairie permettant de lire le contenu des requêtes faites à l’API par l’interface web. En gros, ça analyse le contenu et le ressort de façon compréhensible pour nous.
- chalk : Ca sert pas à grand chose, mais ça permet d’afficher des jolies couleurs dans la console texte.
- chokidar : Sous ce nom barbare se cache ce qui permet à Karaoke Mugen de détecter quand son fichier de configuration a été touché par quelqu’un et de le relire immédiatement.
- cli-progress : Une barre de progression pour le téléchargement des mises à jour
- command-exists : Aide à vérifier si une commande existe dans le shell, ça nous permet de découvrir si git est installé sur votre ordinateur par exemple.
- cookie-parser : Comme pour body-parser, ça permet d’analyser les cookies de votre navigation sur l’interface web de Karaoke Mugen.
- csv-string : On a UN fichier au format CSV, c’est celui des noms alternatifs de séries, et il faut bien qu’on l’analyse aussi
- decompress : Permet de dézipper des archives, utile pour récupérer la dernière version de la base
- download : Pareil, c’est pour la mise à jour de la base.
- execa : Permet de lancer d’autres programmes comme par exemple ffmpeg qui permet à KM de deviner la durée de la vidéo ou encore de calculer son gain audio.
- express : C’est la partie qui crée un serveur web sur lequel vous vous connectez avec votre navigateur !
- express-handlebars : Un système de templates pour sortir des pages web
- express-validator : Permet de s’assurer que ce que vous envoyez à l’API est bien valide. Genre « est-ce que le volume audio envoyé est bien un nombre? »
- file-type : Détecte le type de fichier, on s’en sert surtout pour savoir si vous nous avez bien envoyé une image en changeant d’avatar !
- fs-extra : Des utilitaires pratiques pour gérer les fichiers, par exemple copier tout un dossier
- i18n : C’est ce qui permet d’avoir KM dans plusieurs langues !
- image-size : On peut détecter la taille du papier peint que vous fournissez au lecteur vidéo, et ainsi adapter la taille du QR Code en conséquence.
- ini : Lire les fichiers ini, notamment le fichier de configuration MAIS bien sûr les fichiers .kara qui sont des .ini en fait!
- ip : Détection de votre adresse IP
- iso-countries-languages : J’en ai déjà parlé plus haut, ça permet d’avoir la liste de toutes les langues dans toutes les langues
- jwt-simple : JWT c’est JSON Web Token, ça permet de créer des moyen de vous authentifier sur l’interface web et de savoir que c’est bien vous sans ballader votre login et mot de passe constamment
- langs : J’en ai déjà parlé aussi, ça permet de faire le lien entre des codes de langue.
- localtunnel : Un petit module très sympa pour exposer votre interface web de chez vous au reste du monde. ON l’utilise pour la version initiale de Karaoke Mugen en ligne, mais en vrai on va faire un truc plus pratique bientôt.
- lodash : On a pas mal de dépendences avec certaines fonctions de Lodash, mais plutôt que d’importer toutes les fonctions, on a pris que celles dont on avait besoin. Lodash est une collection de petits utilitaires pratiques comme par exemple selectionner un élément au hasard dans une liste, ou faire un « shuffle » d’une liste.
- minimist : Permet de gérer les arguments de ligne de commande
- multer : Pour accepter les fichiers joints dans un formulaire web, on s’en sert pour les avatars
- node-mpv : Permet de piloter le lecteur vidéo
- os-locale : Détecter la langue de votre système d’exploitation (pour avoir au moins une langue par défaut si on en trouve pas)
- passport et ses modules : Gère l’authentification d’utilisateurs. Ca permet aussi de gérer une authentification via Twitter, Facebook et autres, mais on a pas besoin de tout ça.
- pretty-bytes : Affiche simplement des tailles de fichiers joliement. Par exemple 1.50Mb au lieu de 1500000
- promise-retry : Une petite fonction sympa pour réessayer une promesse qui échoue lamentablement un certain nombre de fois. On s’en sert car SQlite a le défaut de ne pas gérer les requêtes concurrentes, du coup démarrer deux transactions en même temps, ça marche pas trop bien.
- qrcode : Permet de générer le QR Code que vous voyez en haut à gauche
- randomstring : Générer des chaînes aléatoires, avec différents paramètres
- read-chunk : Permet de lire des bouts de fichiers, ça nous permet d’analyser des fichiers pour détecter leur type.
- readline-sync : Sert à attendre que quelqu’un appuie sur une touche, on s’en sert pour Windows où la fenêtre de la console se ferme direct une fois l’application terminée
- semver : Gérer les numéros de version
- simple-git : Passer des commandes git facilement. On s’en sert pour mettre à jour la base de karaokés si vous l’avez sous git
- socket.io : Module indispensable pour gérer les websocket, c’est un petit tuyau entre votre navigateur et KM qui permet de faiclement MAJ certaines infos à l’écran comme par exemple la barre de progression du lecteur vidéo
- sqlite : Le moteur de base de données. On utilise pas celui par défaut (sqlite3) car sqlite l’embarque déjà et propose des petites fioritures comme une meilleure gestion des promesses et un système de migration de bae
- systeminformation : On s’en sert pour savoir combien de moniteurs vous avez et vous permettre de les selectionner pour mpv
- unix-timestamp : On stocke les dates dans ce format !
- uuid : On s’en sert pour donner un identifiant unique à chaque karaoké
- validate.js : Une série de tests pour contrôler si vous nous donnez bien un mail dans votre profil, si telle valeur est un nombre, etc.
- winston : C’est ce qui permet de faire des fichiers log !
L’automatisation
Au fil du développement, j’ai commencé à pêter un câble sur certaines choses que je faisais manuellement, comme mettre en ligne les nouvelles versions. Puis j’ai découvert des choses intéressantes avec le site web et la documentation, et je les ai appliquées au dépôt de l’application.
Gitlab permet en effet de créer des « pipelines » lorsqu’un push est déclenché. Un pipeline est une suite d’actions, des « jobs » qui s’executent à la suite. Par exemple quand on ajoute des modifications au code de Karaoke Mugen, on déclenche grâce à ce procédé une création des fichiers executables et un upload sur le site web. Là où c’est fun c’est qu’on peut également faire déclencher ça sous certaines conditions, par exemple la création d’une version stable, ou ne pas déclencher le pipeline si on fait le push sur certaines branches où ce n’est pas nécessaire.
Voici par exemple le fichier .gitlab-ci.yml de Karaoke Mugen.
Ici on utiliser Docker pour créer un conteneur dans lequel notre pipeline est isolé, et où on passe les commandes. On voit qu’il y a d’abord l’installation de l’app, les tests unitaires, puis on la transpile et on construit les executables windows et mac via pkg dont j’ai parlé plus haut. Enfin, ils sont envoyés par FTP sur le site web de Shelter, et on met à jour la doc de l’API mais seulement si on poste sur la branche master.
Notez qu’il y a des variables comme les login et mot de passe : il est évident qu’on ne va pas mettre ces informations en clair, mais elles sont stockées dans l’interface de Gitlab et passées au conteneur quand il en a besoin.
C’est pas facile de dévlelopper ce genre d’automatisations car parfois on tombe sur des bugs (genre coucou l’ipv6 qui marche pas…) ou des erreurs qu’on ne voit qu’une fois le pipeline lancé. On peut même déclencher d’autres pipelines : par exemple quand on push des modifications sur la base de karaokés, on déclenche aussi le pipeline de reconstruction du site web, car on a mis à jour les informations de la liste des karas !
Pour faire de l’automatisation comme ça, il suffit juste d’installer gitlab-runner sur une machine (la même que gitlab si ça vous chante) et d’enregistrer le runner déjà crée dans votre gitlab. Vous pouvez restreindre l’utilisation du runner à certains projets uniquement, par exemple.
Le site web
Au début on a pensé comme tout le monde a utiliser du WordPress, mais je ne sais plus trop comment, je suis tombé sur le monde fabuleux des générateurs de sites statiques. Contrairement à un blog, le site de Karaoke Mugen n’est qu’une vitrine et n’a pas vocation a être mis à jour souvent. Du coup pourquoi s’embêter à mettre en place une base de données et à faire tourner du php ? Un site statique se charge plus vite et consomme moins de ressources. Sans compter qu’il est du coup automatisable comme j’en parlais plus haut : à chaque modification du dépôt, le site est généré et uploadé sur le serveur web.
Le problème des générateurs c’est que tout le monde et sa soeur en a fait un, et trouver celuiq ui vous convient est pas forcément évident. J’en avais essayé plusieurs et celui qui a retenu mon attention (qui a donné des résultats qui me plaisaient quoi) ce fut Jekyll. Pas forcément le plus simple à mettre en oeuvre (fallait installer Ruby…) mais au final j’en suis plutôt content.
Au delà du choix des outils, il a fallu se poser des questions sur comment naviguer dans un site web pour un logiciel, qu’est-ce qui se fait ailleurs, qu’est-ce que les gens cherchent : comment télécharger, installer, et trouver de l’aide. Ah et puis des infos sur le logiciel aussi, ça peut être pas mal utile. Je pense qu’on a pas fait un travail trop laid sur le site web de Karaoke Mugen mais on est toujours preneurs de suggestions et retours.
Et puis, comme il s’agit d’un dépôt git, ça veut dire que le code est disponible et vous pouvez voir comment on a fait ceci ou cela !
La documentation
Beaucoup de gens semblent oublier qu’un logiciel a besoin d’une bonne doc. On aime pas lire la doc mais elle est nécessaire. Tu peux pas faire en sorte que ton application soit complètement intuitive ou alors ça demande un énorme taff derrière pour gérer l’expérience utilisateur et faire en sorte que personne n’ait à ouvrir le manuel. Hélas, c’est pas si simple quand on est une petite équipe qui cherche avant tout à faire un truc qui fonctionne. Y’a un moment où faut se donner des priorités.
Bref, écrire la doc, c’est pas forcément reluisant, ça demande pas mal de pédagogie et on se demande parfois si on ne détaille pas trop ce qu’on y met, mais on l’a fait pour Karaoke Mugen. C’est le même principe que pour le site web, on a utilisé un générateur de site statique fait pour ça, à savoir MkDocs et on a un dépôt git associé pour voir comment c’est fait. MkDocs fonctionne en Python et est assez facile à utiliser, je n’ai pas grand chose à dire dessus.
Outre la documentation du site il a fallu aussi rédiger celle de l’API pour que de potentiels développeurs puissent s’intéresser à la conception d’un client pour Karaoke Mugen. Cependant il ne faut pas croire que ça ne sert qu’à ça. Ecrire la doc de l’API permet aussi de l’assainir et d’être sûr que ce qu’on écrit reflète bien la réalité. Comme pour le site, la doc de l’API est générée toute seule à partir des commentaires laissés dans le code et le résultat est ensuite uploadé sur cette partie du site. Pour générer cette doc on utilise l’outil apidoc.
Les retours
Maintenant qu’on a fait un peu le tour, on peut s’attaquer aux retours. *rires enregistrés*
Si on a vu quelques utilisateurs curieux essayer, d’autres nous ont rejoint pour aider au projet d’une façon ou d’une autre, mais surtout, ce qui nous a fait le plus plaisir c’est que le logiciel et la base soient utilisés lors de conventions ou d’autres petits évènements. Ainsi, l’asso Belgotaku s’en est servi à Made in Asia le week-end dernier, ou encore Forum Thalie à Japan Expo Sud, et plus récemment on a entendu parler d’autres personnes l’utilisant pour leur école, leur fac’ ou simplement entre potes.
De ce point de vue on peut dire qu’on est heureux que ça soit utilisé. Cela nous met du beaume au coeur et ça
Après, il y a eu aussi d’autres types de retours moins fameux. Il faut bien comprendre qu’en France, certaines associations otakes considèrent leur base de karaoké comme une plusvalue. Plutôt que de mettre tout en commun, chacun préfère faire ça dans son coin quitte à créer les mêmes karaokés que ses voisins et donc perdre un temps fou (ça prend pas mal de temps à faire, sauf pour certains qui sont hyper doués pour timer.) Bref, cette déduplication du travail n’est déjà pas fameuse, sans parler de la compétition un peu malsaine qui en résulte « nous on a ça et ça et ça comme chansons » et « ouais mais nous on a ça » est assez puéril. Au début des années 2000 ça pouvait se voir comme une plus-value, mais aujourd’hui ? Le contenu d’une base de karaokés est-il vraiment significatif ? Pour moi ce qui compte réellement c’est pas d’avoir la plus grosse base ou de se démarquer au niveau des chansons mais d’avoir l’expérience et de savoir comment chauffer une salle, quelles chansons sont les meilleures à passer en kara, ou comment tenter de contenter son public qui va vouloir évidemment passer toutes les chansons du monde. Elle est là la vraie valeur.
Quand en plus on prend en compte le fait que ni les paroles, ni la vidéo, ni la musique n’appartiennent à ces associations (pas plus qu’au projet Karaoke Mugen), il reste quoi ? Le fait de dire qu’à tel moment il faut ouvrir sa bouche et à tel moment dans la vidéo la fermer ? Oui, c’est tout ce qu’il reste.
Heureusement, tous ceux qui sont contre Karaoke Mugen ne nous ont pas approchés de la même façon. Certains bien sûr ont été faire les gros yeux et même menacer jusqu’à ce qu’on leur explique gentiment ce que je viens d’écrire (on en entendit alors plus jamais parler, sauf par des voix détournées où on apprend qu’on est détestés comme la peste et le choléra), et d’autres ont préféré cordialement nous ignorer en public, et venir nous voir pour papoter en privé, sans animosité, juste pour nous exposer leur point de vue.
D’un côté, en mettant à disposition librement une base de karaokés et un logiciel pour gérer des sessions de karaoké, on met entre les mains de tout le monde, conventions comme associations faisant des activités peuvent librement en proposer, et tout le monde est à armes égales. De l’autre, bah ça peut faire un argument de moins pour une asso qui voudrait se vendre à une convention. C’est quelque chose que je peux comprendre ayant géré une association d’activités moi-même. Cependant, j’ai envie de rappeler que ça doit être avant tout les êtres humains qui composent une association qui en font sa force.
Ce qui nous a le plus motivé surtout, c’est de voir l’engouement des fans de karaokés pour avoir une base en commun ou tout le monde peut piocher mais aussi participer. Y’a une vraie demande pour ça et un logiciel de gestion de sessions de karaoké. Cela motive beaucoup plus les gens, je pense, de travailler à un projet commun que chacun dans leur coin. En outre, quand on a parlé avec d’anciens membres d’associations otakes françaises qui ont par le passé géré des activités de karaoké, tout le monde était super content qu’on fasse ça.
Je ne joue pas la vierge effarouchée en parlant de tout ça, car je savais à quoi m’attendre en lançant Karaoke Mugen, mais je pense que c’est important d’avoir les pour et les contre.
Voilà pour le petit coup de gueule de fin de billet
Tout le monde n’est pas comme ça ceci dit, et bizarrement c’est à l’étranger qu’on trouve les fans de karaoké les plus acceuillants : vous vous doutez bien que la France n’a pas le monopole du kara d’anisong, et des groupes comme Soramimi Karaoke organisent eux aussi des events, ont leur propre logiciel et leur base de données. Après avoir parlé avec eux par exemple, nous avons été surpris de trouver des gens super sympa et ouverts qui nous ont permi de piocher dans leur base si on en avait besoin, et inversement pour eux. On compte bientôt l’intégrer dans Karaoke Mugen dés que la sortie de la 2.1 sera derrière nous. Les karaokés de Soramimi sont en mp3 version longue + paroles, mais on peut intégrer ça facilement dans KM. Qui a dit qu’on avait forcément besoin des vidéos ?
Des questions ?
Si vous en avez je serai bien sûr ravi d’y répondre, en commentaire, sur Twitter ou via Discord.
Si ce billet vous a inspiré et vous avez envie de participer, ça tombe bien car on a besoin plus que jamais de gens motivés que ça soit pour remplir les informations manquantes de la base de karaokés, faire des karaokés, remplacer des vidéos de mauvaise qualité, ou encore aider au code de l’application.
Voilà, merci d’avoir lu jusqu’ici !


5 commentaires